
Ik heb deze week de ondertitels voor de film We are as Gods naar het Nederlands omgezet. Op 1 november organiseer ik de Nederlandse vertoning van deze documentaire over Stewart Brand, in het Louis Hartlooper Complex te Utrecht. Ik heb inmiddels een versie van de film in mijn bezit en een los ondertitelbestand ontvangen. Dit zijn standaard tekstbestanden met de extensie .srt (SubRip Fileformat). In dat tekstbestand staat de tijdcode en de teksten. Dit ziet er als volgt uit:
5
00:00:29,741 --> 00:00:32,991
(relaxing piano music)
6
00:00:34,079 --> 00:00:35,329
- There you go.
7
00:00:43,799 --> 00:00:45,343
- [Stewart] Oh, yeah.
8
00:00:45,343 --> 00:00:46,176
- Mammoth.
Dit zijn typische ondertitels voor Amerikaanse films, waar de naam van de spreker staat genoemd en audio-descripties van extra geluiden. Ik vind dat persoonlijk niet altijd even prettig. Toen ik begon aan de Nederlandse vertaling wilde ik die op een eenvoudige manier kunnen verwijderen. Je ziet dat elk blok is genummerd. In totaal zijn er zo’n 1750 blokken. Dat is niet iets wat ik met de hand ga aanpassen natuurlijk. Ik heb de vertaling daarom in de volgende stappen aangepakt:
Vertalen van de tekst
Als eerste heb ik het complete bestand door vertaalsoftware van Engels naar Nederlands omgezet. Dit kan heel eenvoudig met een dienst als Subtitle Translator (gratis, maar doneer een paar euro als je tevreden bent). Je uploadt het bestand met de Engelse tekst en je krijgt netjes een Nederlandse versie terug. Daar ga ik mee werken in de volgende stappen
Regular Expressions
Ik wilde dus twee soorten blokken verwijderen uit het grote tekst bestand, De blokken zoals
5
00:00:29,741 --> 00:00:32,991
(relaxing piano music)en de blokken waar de naam van een spreker in staat vermeld.
7
00:00:43,799 --> 00:00:45,343
- [Stewart] Oh, yeah.De beste manier om dat voor elkaar te krijgen, is met Regular Expressions. Een regular expression, ook wel regex genoemd, is een patroon om tekst te zoeken, te vervangen of te manipuleren. Regular expressions worden vaak gebruikt in programmeertalen, in teksteditors en andere tools waar je met tekst werkt. Je kunt er bijvoorbeeld emailadressen mee valideren, specifieke patronen in een tekst vinden en deze teksten weer aanpassen.
Ik ben niet iemand die zo uit het niets een regex schrijft, gelukkig kunnen AI tools dat prima. Ik besluit Bard van Google eens te testen hiervoor. Ik vraag in een paar iteraties hoe ik de regex moet schrijven om het blok te verwijderen met het patroon van de tekst tussen de haken. Dit heeft altijd het volgende patroon
- een getal tussen 1 en 1750 (het aantal blokken),
- regeleinde
- 2x Tijdcode in de vorm HH:mm:ss,fff gescheiden door “spatie–>spatie”
- regeleinde
- (de tekst)
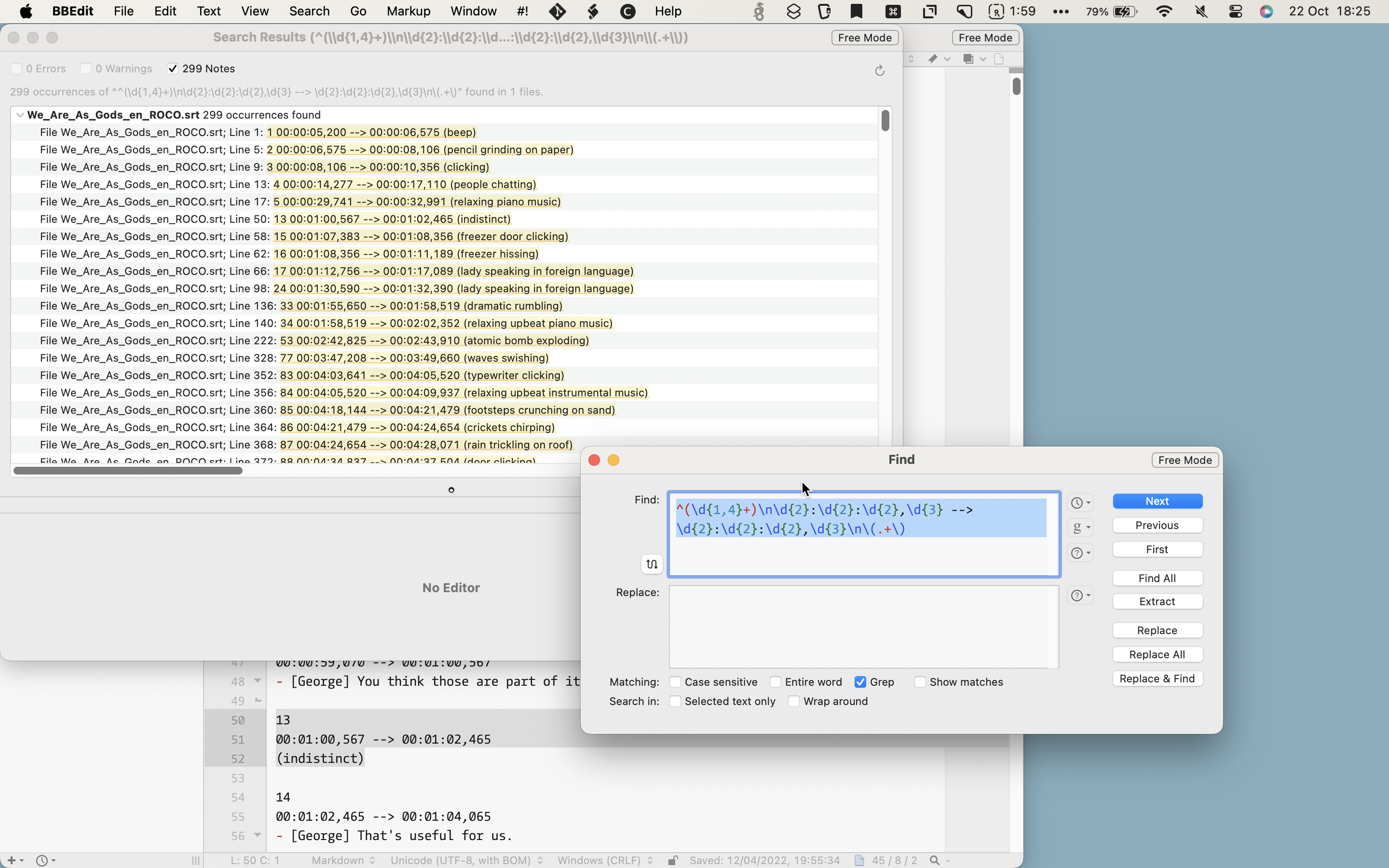
Dat is een patroon voor een regex. Bard brengt me op de goede weg en met de hulp van de website regex101 kan ik stap voor stap mijn regex testen. Uiteindelijk krijg ik voor dit deel de regex
/^(\d{1,4}+)\n\d{2}:\d{2}:\d{2},\d{3} --> \d{2}:\d{2}:\d{2},\d{3}\n\(.+\)/gm
Het lijkt alsof ik random over mijn toetsenbord heb gerold met mijn handen, maar geloof me, hiermee kan ik in een teksteditor zoals BBEdit alle blokken met de audiodescripties verwijderen. Je ziet steeds de letter d gevolgd door een getal. Dit betekent dat de regex zoekt naar een getal (digit) en dat zo vaak herhaalt als het getal wat er staat. Op regex101 krijg je elke stap heel duidelijk uitgelegd en kun je naar hartelust testen.
Achteraf gezien had ik met eenvoudiger expressie net zo goed alleen de tekst kunnen verwijderen, zonder het complete blok. Maar dat vind ik er minder netjes uit zien.
Voor de volledigheid, de regex waarmee ik de tekst kon vinden en aanpassen met de naam van de spreker is
/^(\d{1,4}+)\n\d{2}:\d{2}:\d{2},\d{3} --> \d{2}:\d{2}:\d{2},\d{3}\n\- \[.+] (.+)\n/gm
Met deze regular expressions kan ik in mijn teksteditor (BBEdit) zoeken op de patronen. In BBEdit kan ik met één zoekopdracht alle blokken selecteren en verwijderen.
Maak natuurlijk vooraf een backup van het originele bestand. Nu heb ik een Nederlands ondertitel bestand wat voor 90% al best goed is om te gebruiken. Ik had echter in de Engelse versie al gezien dat de timing niet altijd even strak was én dat sommige woorden vreemd waren ondertiteld. Tijd om dat te fixen!
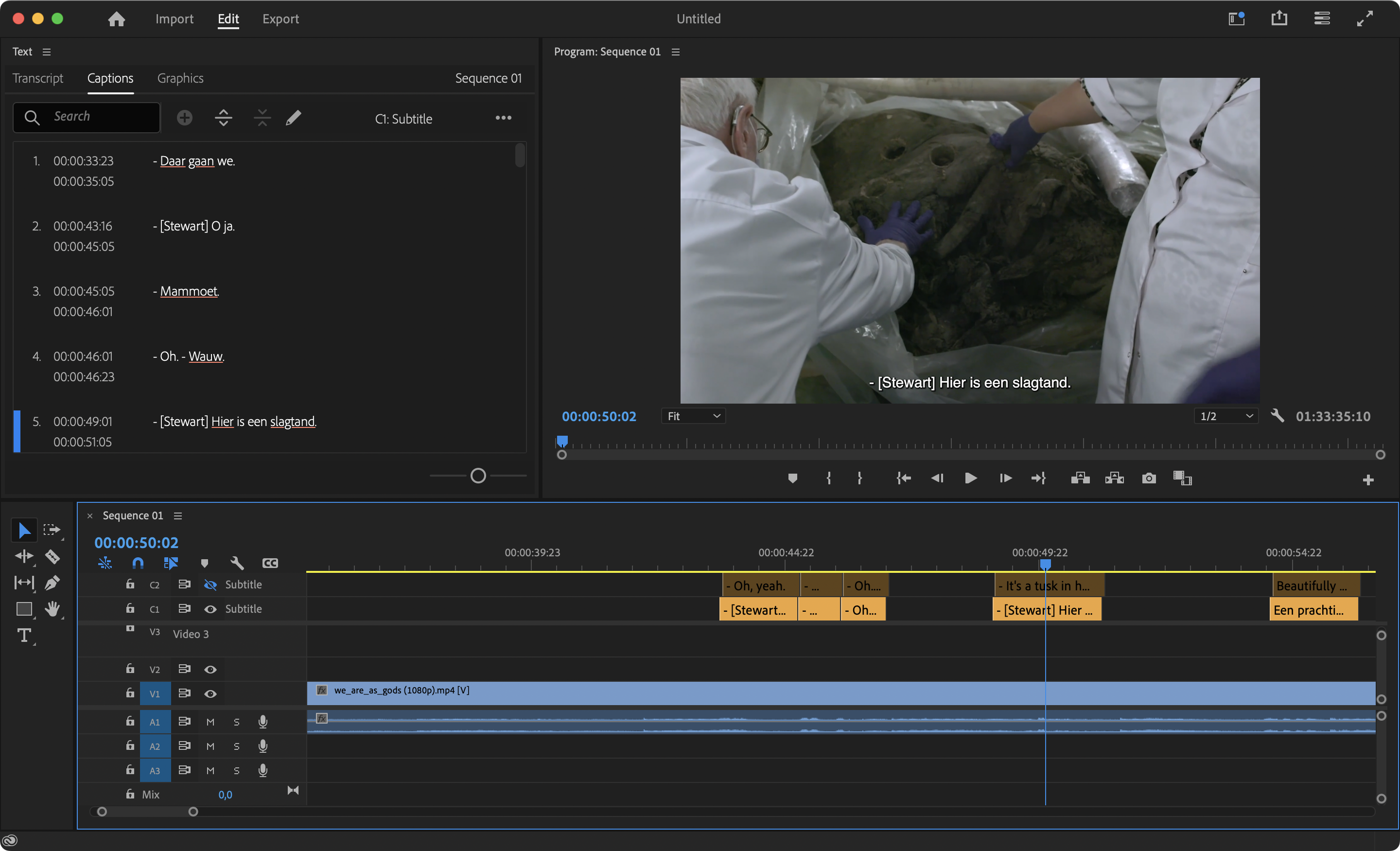
Tekst aanpassen en timing
In Adobe Premiere Pro (onderdeel van het Creative Cloud pakket) kan ik zowel de film als het ondertitel bestand laden. Er zijn talloze andere oplossingen te vinden, maar Premiere heb ik nu eenmaal al op mijn Mac staan. Nu kan ik per blok de tekst aanpassen en de timing simpelweg slepen naar het juiste moment. Een precies klusje, maar tegelijk geeft het me wel de voldoening dat ik de ondertitels echt goed naar mijn wens kan maken. Met een paar handige sneltoetsen kan ik redelijk snel door de film en de tekst. Misschien zijn er nog eenvoudiger manieren om dit te doen, maar dit werkte goed genoeg voor me.
Stijl en vorm
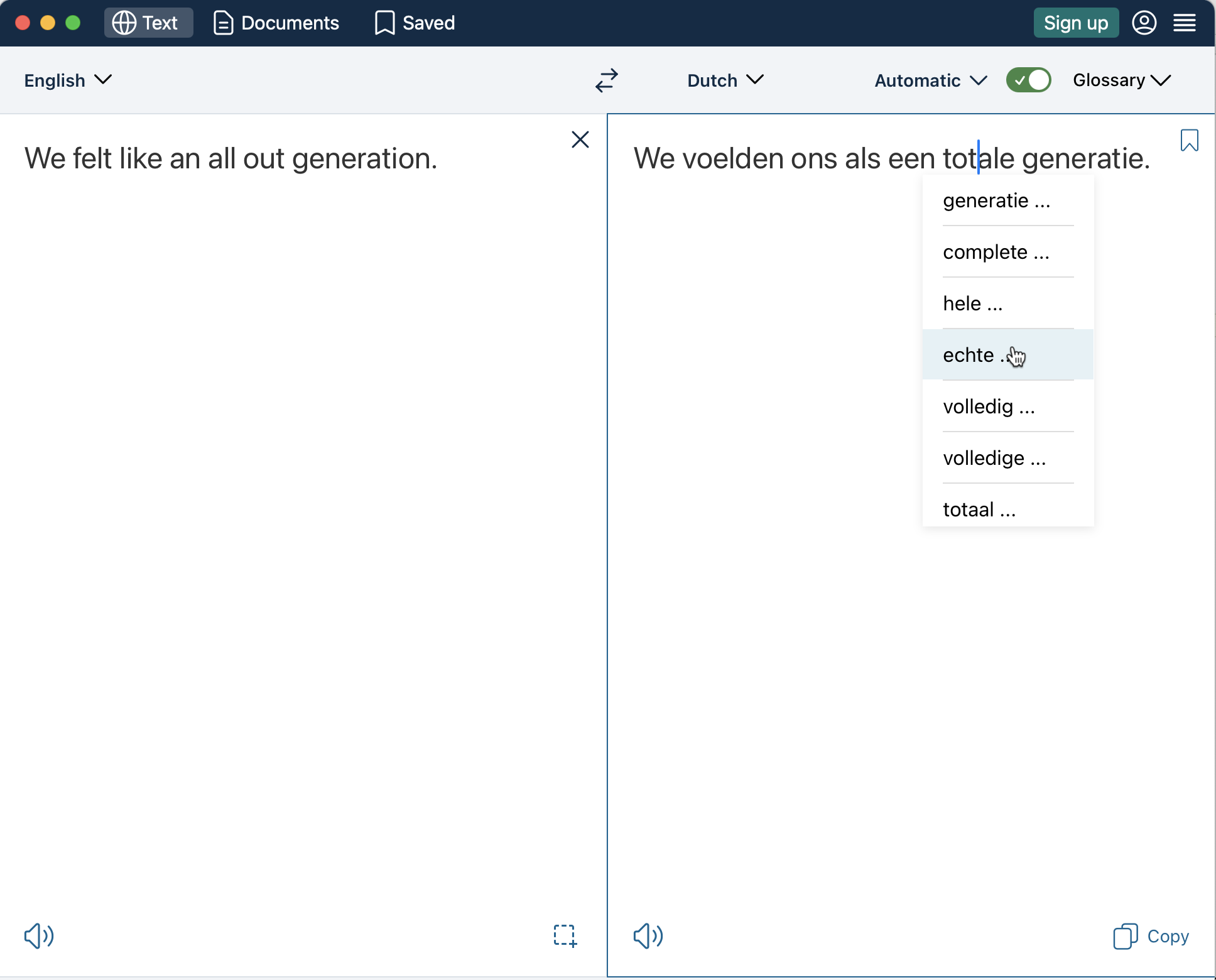
Vertalingen maken is nieuw voor me. Ik ben er lang mee bezig geweest. Zo’n 5 – 6 uur verdeeld over 2 dagen. Maar ik heb bij elke uitspraak in de film na kunnen denken wát er nu eigenlijk wordt gezegd en wat de beste manier is om dat in het Nederlands over te brengen, binnen de tijd dat er wordt gesproken. Soms gebruikte ik een woord met meer lettergrepen, omdat het een betere vertaling is. Dan is het fijn als ik die een halve seconde langer kan laten staan, zodat de kijker iets meer tijd heeft om het op te nemen. Soms maakte ik van een complexe Engelse uitleg een simpeler vertaling met minder woorden. Soms moest ik een lange zin over twee regels plaatsen, soms knipte ik het in twee blokken. Zodat je de zinnen na elkaar ziet. Het ligt maar net aan de scene, het tempo waarin wordt gesproken en hoe complex de tekst is. Met behulp van de vertaalsoftware Deepl en synoniemen.net kon ik eveneens meer variatie in de teksten brengen.
Conclusie
Ik hoop dat de Nederlandse ondertitels een positief effect hebben op de beleving van de film. Tijdens het vertalen heb ik scenes meerdere keren bekeken, waardoor ik niet meer met frisse blik naar de ondertitels kon kijken. Ik wilde op dat moment het juiste woord vinden en vergat dan hoe de tekst overkwam bij de scene. Daarom kijk ik over een paar dagen de film nog eens in zijn geheel met de Nederlandse ondertitels. Hopelijk kan ik ze dan objectiever beoordelen.
