
Eén van de principes van het indieweb is “scratching your own itch”, als je iets nodig hebt voor je site of je project, dan kun je altijd proberen het zelf te maken. Vandaag merkte ik weer wat een goed gevoel dat kan geven. Setlist informatie Ik ben bezig met een artikel voor Chordify.net over de…
nodejs
Public Folder, host je website lokaal en bij Amazon.
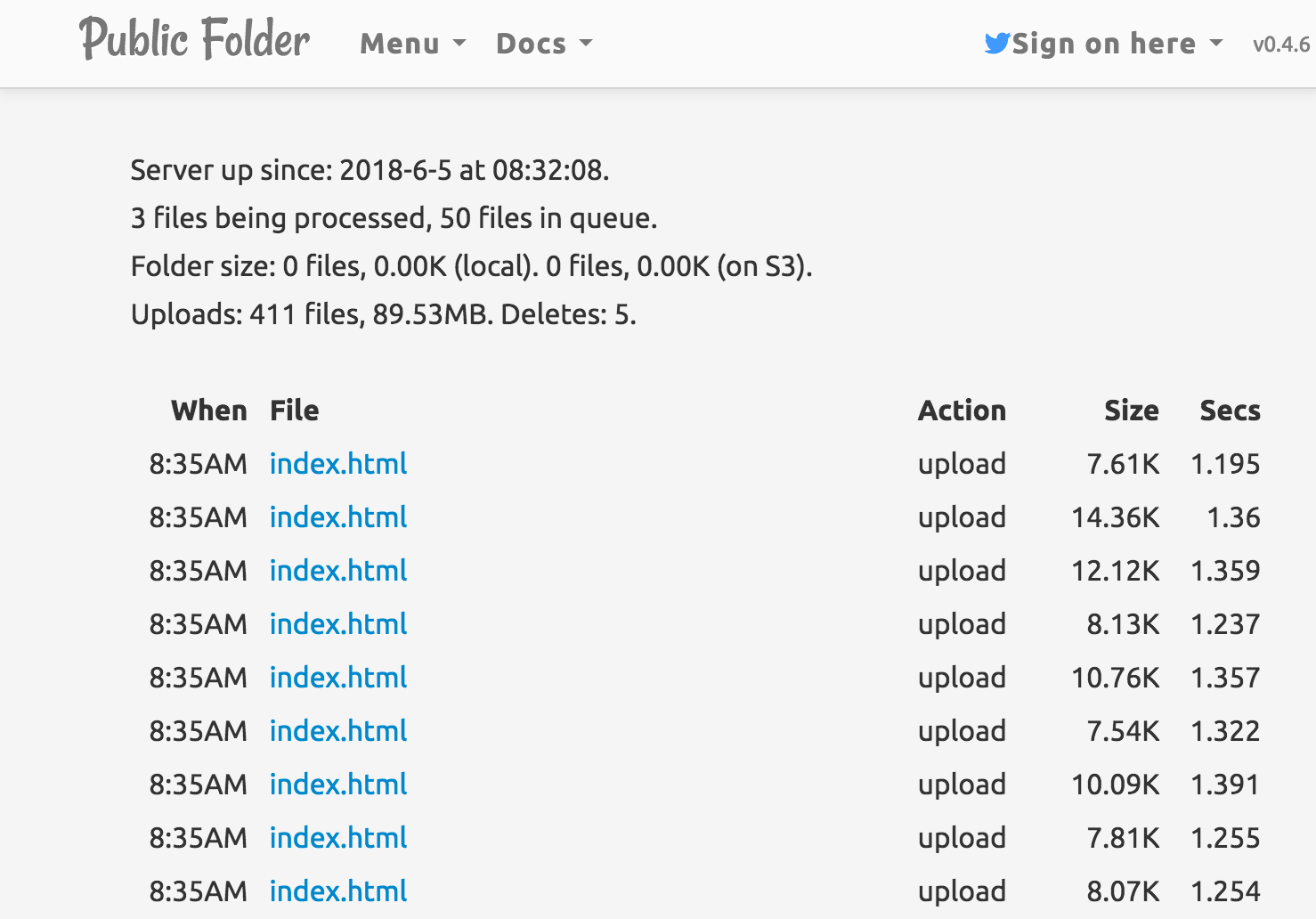
Ik was vanochtend eigenlijk op zoek in mijn Programma’s map of ik nog een offline RSS-lezer had. Zover kwam ik niet, want mijn oog viel op het programma PublicFolder. Ik wist eerst even niet wat het was maar nadat ik het opende zag ik al snel dat het een projectje van Dave Winer was. Een…
72 regels code als oplossing
Een van de principes in het Indieweb-denken is “selfdogfood”, het idee dat je bouwt wat je zelf nodig hebt en gebruikt wat je zelf bouwt. Dit in tegenstelling tot de vele diensten die het werk uit handen nemen in de vorm van plugins, betaalde SaaS oplossingen of software waarvan je eigenlijk niet exact weet wat…
Hoe ik mijn eigen oplossingen maak met code en doorzettingsvermogen.
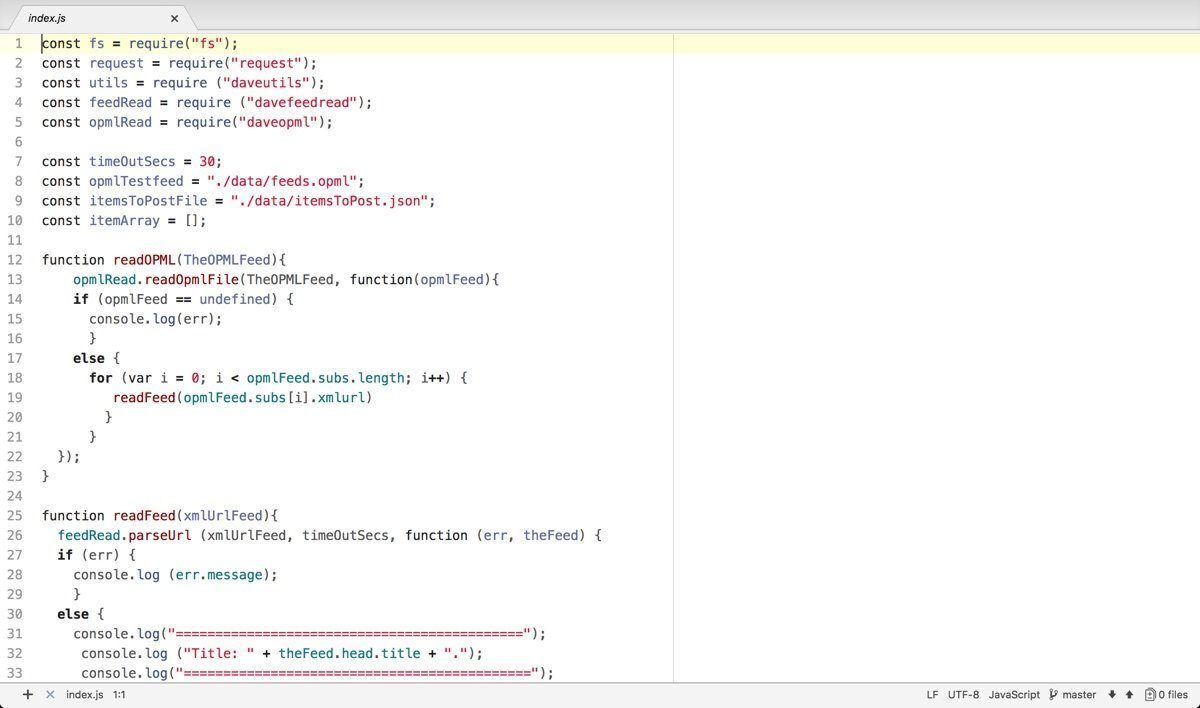
De afgelopen dagen ben ik wat aan het knutselen geraakt met de programmeertaal NodeJS. Bij Olisto wordt vrijwel alles in deze taal geschreven en recent had ik de behoefte om een intern hulpmiddel voor onze helpdesk wat te verbeteren. Omdat al onze ontwikkelaars druk bezig zijn met de app zelf, besloot ik de mouwen op…
